Accent-Folding for Autocomplete
Another generation of technology has passed and Unicode support is almost everywhere. The next step is to write software that is not just “internationalized” but truly multilingual. In this article we will skip through a bit of history and theory, then illustrate a neat hack called accent-folding. Accent-folding has its limitations but it can help make some important yet overlooked user interactions work better.

Illustration by Kevin Cornell
(Originally appeared on A List Apart.)
A common assumption about internationalization is that every user fits into a single locale like “English, United States” or “French, France.” It’s a hangover from the PC days when just getting the computer to display the right squiggly bits was a big deal. One byte equaled one character, no exceptions, and you could only load one language’s alphabet at a time. This was fine because it was better than nothing, and because users spent most of their time with documents they or their coworkers produced themselves.
Today users deal with data from everywhere, in multiple languages and locales, all the time. The locale I prefer is only loosely correlated with the locales I expect applications to process.
Consider this address book:
- Fulanito López
- Erik Lørgensen
- Lorena Smith
- James Lö
If I compose a new message and type “lo” in the To: field, what should happen? In many applications only Lorena will show up. These applications “support Unicode,” in the sense that they don’t corrupt or barf on it, but that’s all.
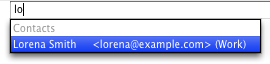
Fig 1. Hey Entourage, where are my contacts?
This problem is not just in address books. Think about inboxes, social bookmarks, comment feeds, users who speak multiple languages, users in internet cafés in foreign countries, even URLs. Look at the journalist Ryszard Kapuściński and how different websites handle his name:
- Wikipedia: Ryszard Kapuściński (canonical URL)
- Wikipedia: Ryszard Kapuscinski (hand-coded alternate)
- Wikipedia: Ryszard Kapusciński (not found)
- Wikipedia: Rÿszarḋ Kåpuścińsḳi (not found)
- Spock: Rÿszarḋ Kåpuścińsḳi (accent-folded, redirects to canonical URL)
There is no excuse for your software to play dumb when the user types “cafe” instead of “café.”
Áçčềñṭ-Ḟøłɖǐṅg
In specific applications of search that favor recall over precision, such as our address book example, á, a, å, and â can be treated as equivalent. Accents (a.k.a diacritical marks) are pronunciation hints that don’t affect the textual meaning. Entering them can be cumbersome, especially on mobile devices.
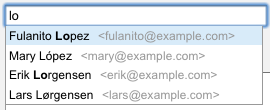
Fig 2. accent-folding in an autosuggest widget
An accent-folding function essentially maps Unicode characters to ASCII equivalents. Anywhere you apply case-folding, you should consider accent-folding, and for exactly the same reasons. With accent-folding, it doesn’t matter whether users search for cafe, café or even çåFé; the results will be the same.
Be aware that there are a million caveats to accent rules. You will almost certainly get it wrong for somebody, somewhere. Nearly every alphabet has a few extra-special marks that do affect meaning, and, of course, non-Western alphabets have completely different rules.
A minor gotcha is the Unicode "fullwidth" Roman alphabet. These are fixed-width versions of plain ASCII characters designed to line up with Chinese/Japanese/Korean characters (e.g., "1979年8月15日"). They reside in 0xff00 to 0xff5e and should be treated as equivalent to their ASCII counterparts.
Hey man, I’m only here for the copy/paste
I’ve posted more complete examples on GitHub, but for illustration, here’s a basic accent-folder in Javascript:
var accentMap = { 'á':'a', 'é':'e', 'í':'i','ó':'o','ú':'u' }; function accent_fold (s) { if (!s) { return ''; } var ret = ''; for (var i = 0; i < s.length; i++) { ret += accent_map[s.charAt(i)] || s.charAt(i); } return ret; };
Regular Expressions
Regular expressions are very tricky to make accent-aware. Notice that in Fig. 2 only the unaccented entries are in bold type. The problem is that the Unicode character layout does not lend itself to patterns that cut across languages. The proper regex for “lo” would be something insane like:
[LlĹ弾ĻļḶḷḸḹḼḽḺḻŁłŁłĿŀȽƚɫ][OoÓóÒòŎŏÔôỐốỒồỖöȪȫŐőÕõṌȭȮȯǾǿ...ǬǭŌ]Never, never do this. As of this writing, few regular expression engines support shortcuts for Unicode character classes. PCRE and Java seem to be in the vanguard. You probably shouldn’t push it. Instead, try highlighting an accent-folded version of the string, and then use those character positions to highlight the original, like so:
// accent_folded_hilite("Fulanilo López", 'lo') // --> "Fulani<b>lo</b> <b>Ló</b>pez" // function accent_folded_hilite(str, q) { var str_folded = accent_fold(str).toLowerCase().replace(/[<>]+/g, ''); var q_folded = accent_fold(q).toLowerCase().replace(/[<>]+/g, ''); // Create an intermediate string with hilite hints // Example: fulani<lo> <lo>pez var re = new RegExp(q_folded, 'g'); var hilite_hints = str_folded.replace(re, '<'+q_folded+'>'); // Index pointer for the original string var spos = 0; // Accumulator for our final string var highlighted = ''; // Walk down the original string and the hilite hint // string in parallel. When you encounter a < or > hint, // append the opening / closing tag in our final string. // If the current char is not a hint, append the equiv. // char from the original string to our final string and // advance the original string's pointer. for (var i = 0; i< hilite_hints.length; i++) { var c = str.charAt(spos); var h = hilite_hints.charAt(i); if (h === '<') { highlighted += '<b>'; } else if (h === '>') { highlighted += '</b>'; } else { spos += 1; highlighted += c; } } return highlighted; }
The previous example is probably too simplistic for production code. You can’t highlight multiple terms, for example. Some special characters might expand to two characters, such as “æ” --> “ae” which will screw up spos. It also strips out angle-brackets (<>) in the original string. But it’s good enough for a first pass.
Accent-folding in YUI Autocomplete
YUI's Autocomplete library has many hooks and options to play with. Today we’ll look at two overrideable methods: filterResults() and formatMatch(). The filterResults method allows you to write your own matching function. The formatMatch method allows you to change the HTML of an entry in the list of suggested matches. You can also download a complete, working example with all of the source code.
<!-- this is important to tell javascript to treat the strings as UTF-8 --> <meta http-equiv="content-type" content="text/html;charset=utf-8" /> <!-- YUI stylesheets --> <link rel="stylesheet" type="text/css" href="http://yui.yahooapis.com/2.7.0/build/fonts/fonts-min.css" /> <link rel="stylesheet" type="text/css" href="http://yui.yahooapis.com/2.7.0/build/autocomplete/assets/skins/sam/autocomplete.css" /> <!-- YUI libraries: events, datasource and autocomplete --> <script type="text/javascript" src="http://yui.yahooapis.com/2.7.0/build/yahoo-dom-event/yahoo-dom-event.js"></script> <script type="text/javascript" src="http://yui.yahooapis.com/2.7.0/build/datasource/datasource-min.js"></script> <script type="text/javascript" src="http://yui.yahooapis.com/2.7.0/build/autocomplete/autocomplete-min.js"></script> <!-- contains accent_fold() and accent_folded_hilite() --> <script type="text/javascript" src="accent-fold.js"></script> <!-- Give <body> the YUI "skin" --> <body class="yui-skin-sam"> <b>To:</b> <div style="width:25em"> <!-- Our to: field --> <input id="to" type="text" /> <!-- An empty <div> to contain the autocomplete --> <div id="ac"></div> </div> </body> <script> // Our static address book as a list of hash tables var addressBook = [ {name:'Fulanito López', email:'fulanito@example.com'}, {name:'Erik Lørgensen', email:'erik@example.com'}, {name:'Lorena Smith', email:'lorena@example.com'}, {name:'James Lö', email:'james@example.com'} ]; /* Iterate our address book and add a new field to each row called "search." This contains an accent-folded version of the "name" field. */ for (var i = 0; i< addressBook.length; i++) { addressBook[i]['search'] = accent_fold(addressBook[i]['name']); } // Create a YUI datasource object from our raw address book var datasource = new YAHOO.util.LocalDataSource(addressBook); /* A datasource is tabular, but our array of hash tables has no concept of column order. So explicitly tell the datasource what order to put the columns in. */ datasource.responseSchema = {fields : ["email", "name", "search"]}; /* Instantiate the autocomplete widget with a reference to the input field, the empty div, and the datasource object. */ var autocomp = new YAHOO.widget.AutoComplete("to", "ac", datasource); // Allow multiple entries by specifying space // and comma as delimiters autocomp.delimChar = [","," "]; /* Add a new filterResults() method to the autocomplete object: Iterate over the datasource and search for q inside the "search" field. This method is called each time the user types a new character into the input field. */ autocomp.filterResults = function(q, entries, resultObj, cb) { var matches = []; var re = new RegExp('\\b'+accent_fold(q), 'i'); for (var i = 0; i < entries.length; i++) { if (re.test(entries[i]['search'])) { matches.push(entries[i]); } } resultObj.results = matches; return resultObj; }; /* Add a new formatResult() method. It is called on each result returned from filterResults(). It outputs a pretty HTML representation of the match. In this method we run the accent-folded highlight function over the name and email. */ autocomp.formatResult = function (entry, q, match) { var name = accent_folded_hilite(entry[1], q); var email = accent_folded_hilite(entry[0], q); return name + ' <' + email + '>'; }; //fin </script>
About those million caveats...
This accent-folding trick works primarily for Western European text, but it won’t work for all of it. It exploits specific quirks of the language family and the limited problem domains of our examples, where it’s better to get more results than no results. In German, Ü should probably map to Ue instead of just U. A French person searching the web for thé (tea) would be upset if flooded with irrelevant English text.
You can only push a simple character map so far. It would be very tricky to reconcile the Roman “Marc Chagall” with the Cyrillic “Марк Шагал” or Hebrew “מאַרק שאַגאַל.” There are very interesting similarities in the characters but a magical context-free two-way mapping is probably not possible.
On top of all that there is another problem: One language can have more than one writing system. Transliteration is writing a language in a different alphabet. It’s not quite the same as transcription, which maps sounds as in “hola, que paso” --> “oh-la, keh pah-so.” Transliterations try to map the written symbols to another alphabet, ideally in a way that’s reversible.
These four sentences all say “Children like to watch television” in Japanese:
- One Way: 子供はテレビを見るのが好きです。
- Another Way: こども は てれび を みる の が すき です 。
- Romaji: kodomo wa terebi o miru noga suki desu.
- Cyrillic: кодомо ва тэрэби о миру нога суки дэсу.
For centuries people have been inventing ways to write different languages with whatever keyboards or typesetting they had available. So even if the user reads only one language, they might do so in multiple transliteration schemes. Some schemes are logical and academic, but often they are messy organic things that depend on regional accent and historical cruft. The computer era kicked off a new explosion of systems as people learned to chat and send emails in plain ASCII.
There is a lot of prior work on this problem and two ready paths you can choose: The right way and the maybe-good-enough way. Neither have the simplicity of our naïve hash table, but they will be less disappointing for your users in general applications.
The first is International Components for Unicode (ICU), a project that originated in the early nineties at Taligent. It aims to be a complete, language-aware transliteration, Unicode, formatting, everything library. It’s big, it’s C++/Java, and it requires contextual knowledge of the inputs and outputs to work.
The second is Unidecode, a context-free transliteration library available for Perl and Python. It tries to transliterate all Unicode characters to a basic Latin alphabet. It makes little attempt to be reversible, language-specific, or even generally correct; it’s a quick-and-dirty hack that nonetheless is pretty comprehensive.
Accent-folding in the right places saves your users time and makes your software smarter. The strict segregation of languages and locales is partially an artifact of technology limitations which no longer hold. It’s up to you how far you want to take things, but even a little bit of effort goes a long way. Good luck!